The Surprising Ineffectiveness of Pre-Trained Visual Representations for Model-Based Reinforcement Learning
TL;DR
Our results challenge some common assumptions about the benefits of PVRs in MBRL and highlight the importance of data diversity and reward prediction accuracy.
Abstract
Visual Reinforcement Learning (RL) methods often require extensive amounts of data. As opposed to model-free RL, model-based RL (MBRL) offers a potential solution with efficient data utilization through planning. Additionally, RL lacks generalization capabilities for real-world tasks. Prior work has shown that incorporating pre-trained visual representations (PVRs) enhances sample efficiency and generalization. While PVRs have been extensively studied in the context of model-free RL, their potential in MBRL remains largely unexplored. In this paper, we benchmark a set of PVRs on challenging control tasks in a model-based RL setting. We investigate the data efficiency, generalization capabilities, and the impact of different properties of PVRs on the performance of model-based agents. Our results, perhaps surprisingly, reveal that for MBRL current PVRs are not more sample efficient than learning representations from scratch, and that they do not generalize better to out-of-distribution (OOD) settings. To explain this, we analyze the quality of the trained dynamics model. Furthermore, we show that data diversity and network architecture are the most important contributors to OOD generalization performance.
Method
Our study uses DreamerV3 and TD-MPC2 algorithms, known for their state-of-the-art performance. These algorithms are integrated with PVRs by replacing the encoder with a frozen PVR and a linear mapping. The rest of the MBRL algorithms remain unchanged. Using this setup, we evaluate various PVRs, including popular models like CLIP and less common ones like mid-level representations. All models are open-source and trained on self-supervised objectives using Vision Transformers (ViT) or ResNets. For better comparison purposes we also include custom pre-trained autoencoders trained on task-specific data.
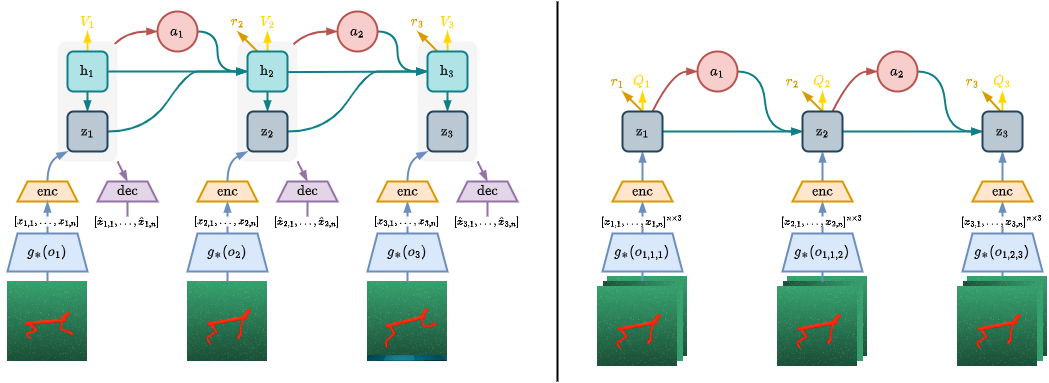 Components of our PVR-based DreamerV3 (left) and TD-MPC2 (right) architectures.
In DreamerV3, the output of the frozen pre-trained vision module is given to the encoder which maps
its input to a discrete latent variable. In TD-MPC2 a stack of the last 3 PVR embeddings is given to
the encoder which maps the inputs to fixed-dimensional simplices. The encoder of DreamerV3
additionally requires the recurrent state as input. The rest of both algorithms are not
changed.
Components of our PVR-based DreamerV3 (left) and TD-MPC2 (right) architectures.
In DreamerV3, the output of the frozen pre-trained vision module is given to the encoder which maps
its input to a discrete latent variable. In TD-MPC2 a stack of the last 3 PVR embeddings is given to
the encoder which maps the inputs to fixed-dimensional simplices. The encoder of DreamerV3
additionally requires the recurrent state as input. The rest of both algorithms are not
changed.
The evaluation spans 10 control tasks from three domains: DeepMind Control Suite (DMC), ManiSkill2, and Miniworld. All tasks use 256x256 RGB images for observations. The agents are trained under a distribution of visual changes in the environment (which we refer to as In Distribution (ID) and are evaluated later under a different distribution of unseen changes (OOD changes). ID training and OOD evaluation are implemented through randomizations of visual attributes in the environments by splitting all possible randomizations into ID training and OOD evaluation sets. We focus exclusively on the setting of visual distribution shifts.
Results
Data Efficiency
Our study investigates the sample efficiency of PVR-based MBRL agents compared to agents using visual representations learned from scratch. Contrary to expectations, representations learned from scratch are often equally or more data-efficient than PVRs. This challenges the belief that PVRs accelerate MBRL training, possibly due to an objective mismatch in MBRL.
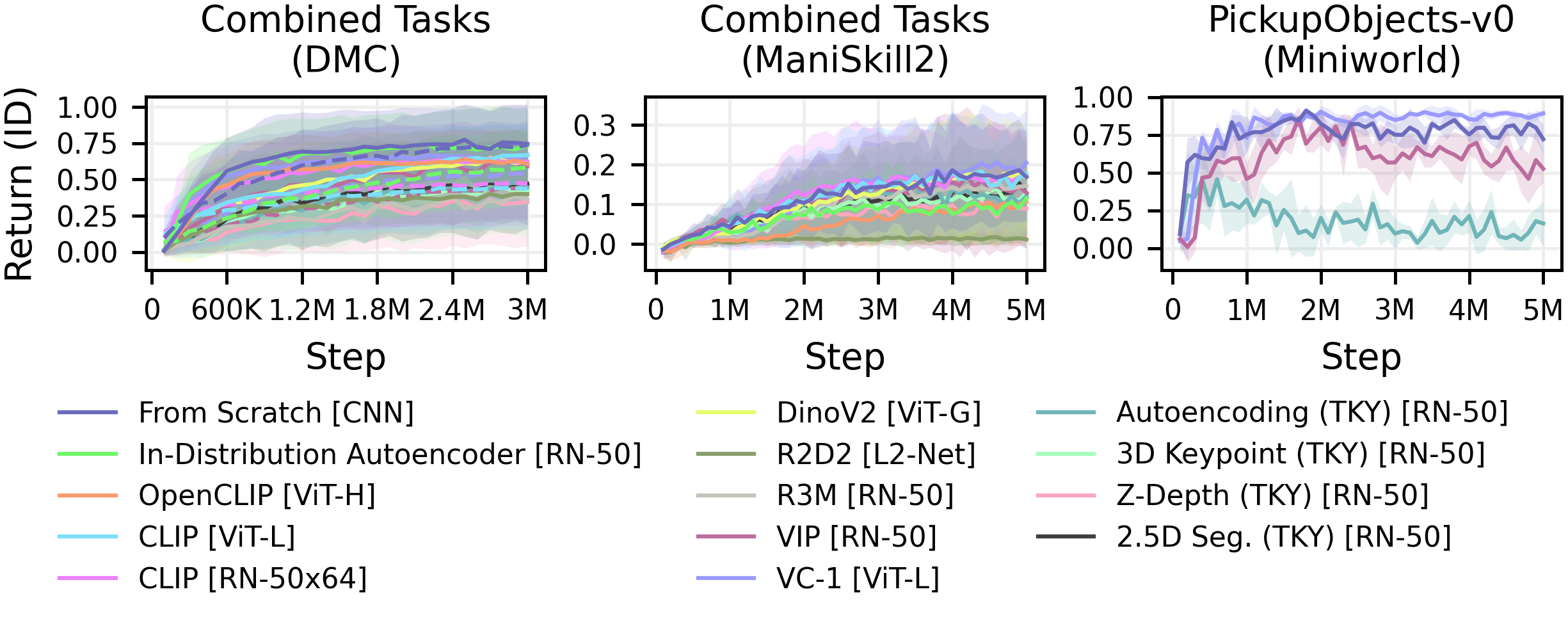 ID performance and data-efficiency comparison on DMC, ManiSkill2 and
Miniworld environments between the different representations. Each line represents the mean over all
runs with a given representation, the shaded area represents the corresponding standard deviation.
Solid lines represent DreamerV3 runs, whereas dashed lines indicate TD-MPC2 experiments. Especially
in the DMC experiments, representations trained from scratch outperform all PVRs also in terms of
data-efficiency.
ID performance and data-efficiency comparison on DMC, ManiSkill2 and
Miniworld environments between the different representations. Each line represents the mean over all
runs with a given representation, the shaded area represents the corresponding standard deviation.
Solid lines represent DreamerV3 runs, whereas dashed lines indicate TD-MPC2 experiments. Especially
in the DMC experiments, representations trained from scratch outperform all PVRs also in terms of
data-efficiency.
Generalization to OOD Settings
The research evaluates the out-of-distribution (OOD) performance of PVRs. The results show that, except for VC-1, PVRs do not perform well in OOD domains compared to representations learned from scratch. This is surprising given that some PVRs are trained on diverse data sets.
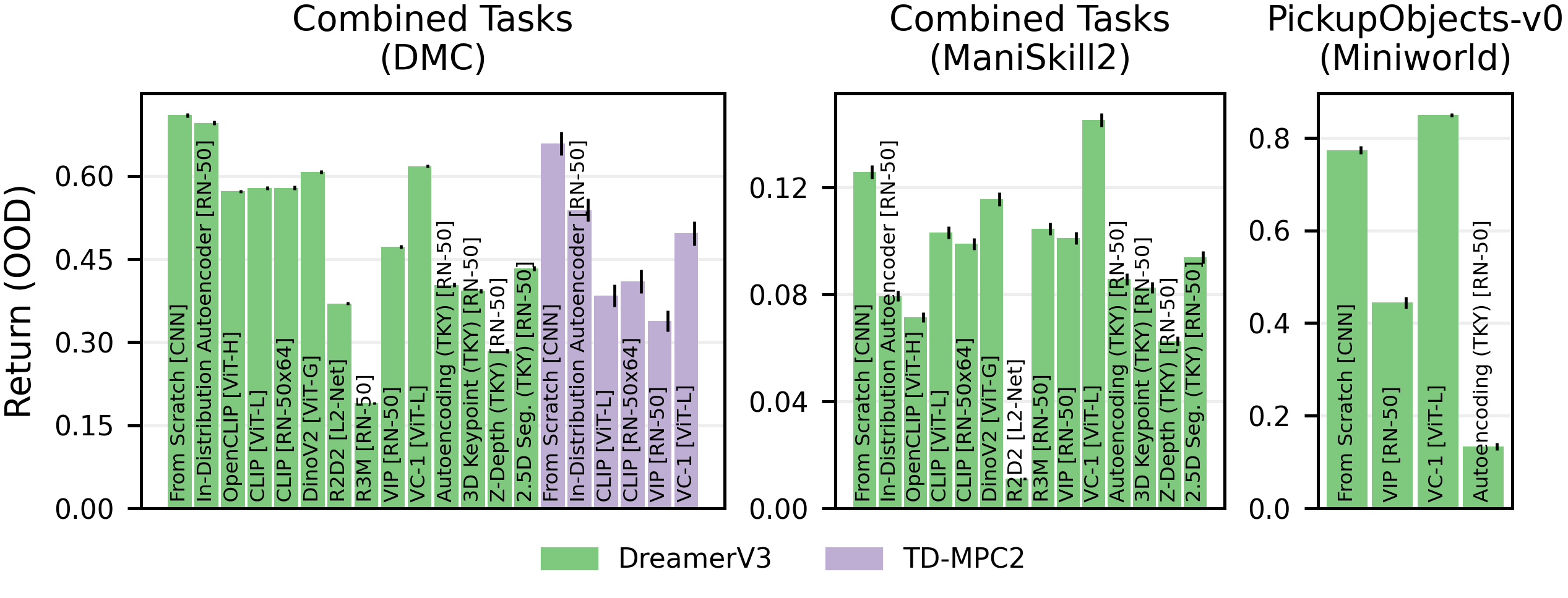 Average performance on DMC, ManiSkill2 and Miniworld tasks in the OOD setting.
The baseline representation learned from scratch outperforms all PVRs, even in the OOD settings.
Thin black lines denote the standard error.
Average performance on DMC, ManiSkill2 and Miniworld tasks in the OOD setting.
The baseline representation learned from scratch outperforms all PVRs, even in the OOD settings.
Thin black lines denote the standard error.
Properties of PVRs for Generalization
Our study examines which properties of PVRs are relevant for OOD generalization. We find that language conditioning is not necessary for good OOD generalization, while data diversity is generally important. Vision Transformer (ViT) architectures perform well, but data diversity appears more crucial than the network architecture of the encoder.
 IQM return of the different categorizations. Each marker represents
the interquartile-mean performance of an individual group. The x-axis shows the ID performance and
the y-axis the OOD performance. Especially, ViT representations or representations trained on
diverse data perform well in the OOD setting. Sequential data seem to help in ManiSkill2
and Miniworld but not in DMC.
IQM return of the different categorizations. Each marker represents
the interquartile-mean performance of an individual group. The x-axis shows the ID performance and
the y-axis the OOD performance. Especially, ViT representations or representations trained on
diverse data perform well in the OOD setting. Sequential data seem to help in ManiSkill2
and Miniworld but not in DMC.
World Model Differences
Based on our results so far, we finally investigate how different visual representations affect the quality of the world model in MBRL. We analyze dynamics prediction error and reward prediction error, finding that reward prediction accuracy is more important for performance. PVRs may not provide enough information to predict rewards as accurately as representations learned from scratch.
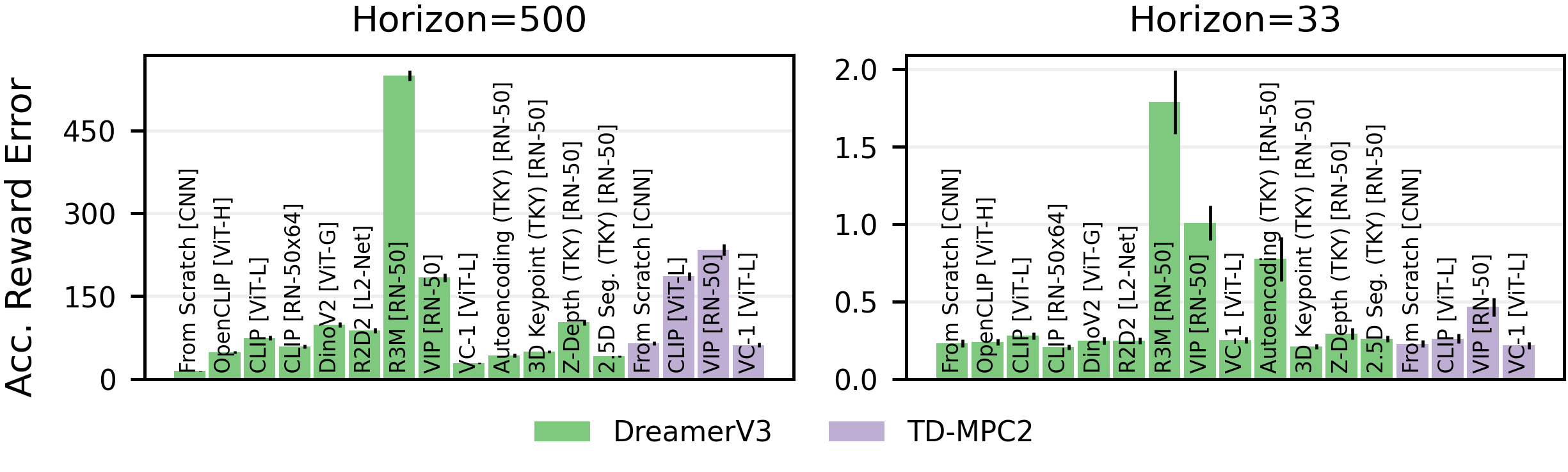 Average Accumulated Reward Errors on the Pendulum Swingup
task for 200 trajectories. The error is calculated as the absolute difference between true and
predicted reward. Thin black lines denote the standard error.
Average Accumulated Reward Errors on the Pendulum Swingup
task for 200 trajectories. The error is calculated as the absolute difference between true and
predicted reward. Thin black lines denote the standard error.
PVRs are trained to compress information as bottlenecks, often excluding reward-relevant data since reward information is not part of their training objectives. In contrast, MBRL methods like DreamerV3 and TD-MPC2 prioritize reward information. Benchmarks of PVRs typically focus on imitation learning, where reward information is irrelevant.
To investigate reward-related data in representations, we analyze UMAP projections of the latent state space in the Pendulum Swingup task. Representations learned from scratch and similar performing methods like VC-1 clearly encode reward information, with states of similar rewards clustered together. This lack of reward embedding in many PVRs may explain their underperformance compared to learned-from-scratch representations. Accurate reward extraction is essential for learning effective policies, which is hindered if reward information is not consistently embedded.
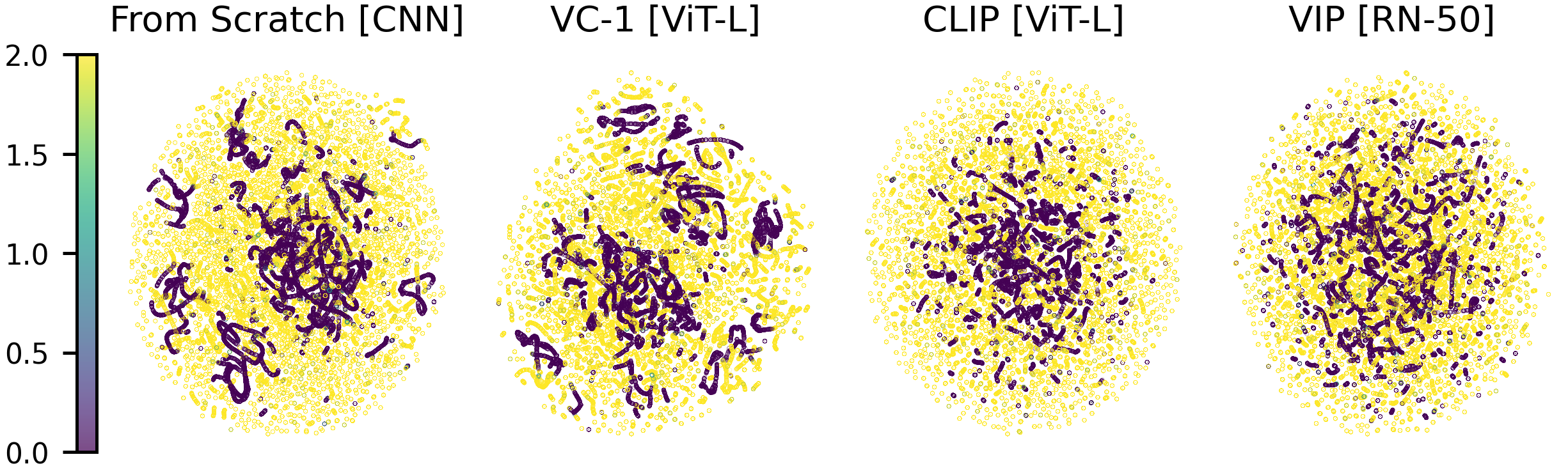
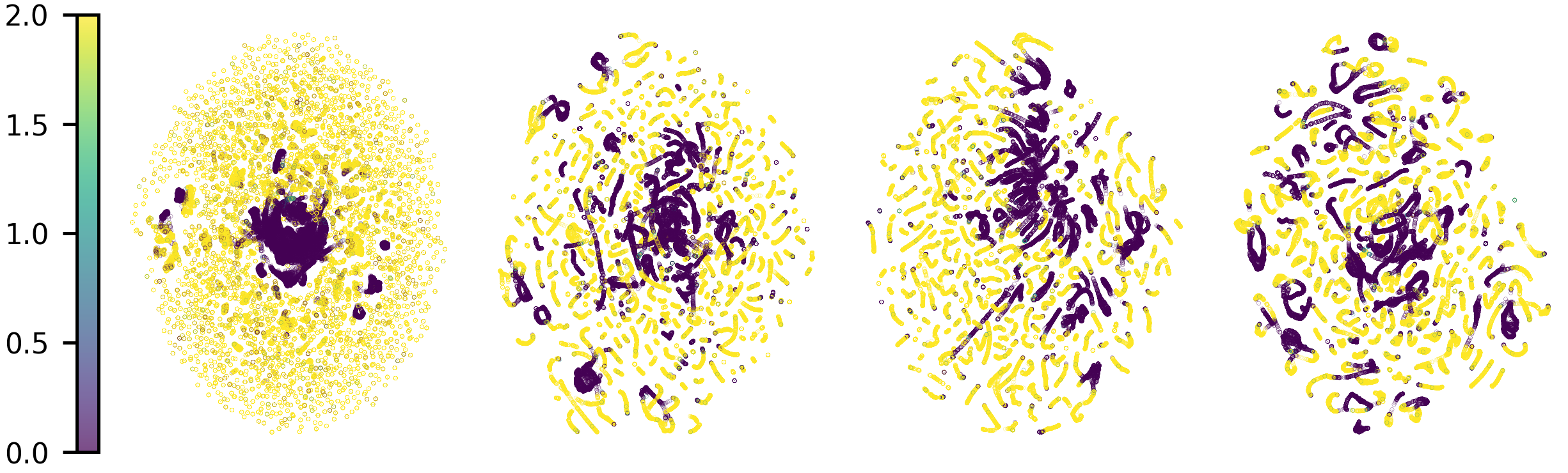 UMAP projections of DreamerV3 (top row) and TD-MPC2 (bottom row)
encodings using different representations as input. The points are color coded by the real
perceived reward. Each point represents a visited state in the Pendulum Swingup environment
of DMC. The representations learned from scratch better disentangle low and high reward states
whereas the embeddings of the PVRs are more entangled.
UMAP projections of DreamerV3 (top row) and TD-MPC2 (bottom row)
encodings using different representations as input. The points are color coded by the real
perceived reward. Each point represents a visited state in the Pendulum Swingup environment
of DMC. The representations learned from scratch better disentangle low and high reward states
whereas the embeddings of the PVRs are more entangled.